

Content Engineering: How to Build Your Content System in Claude Code
How one CMO built a knowledge base for an AI-powered GTM engine. Free GitHub repo inside.



This newsletter is sponsored by Miro.
I’ve helped 10,000+ companies build their GTM plan. I know exactly where they get stuck. Every time, it’s the same three things:
Too many GTM ideas, no way to cut through them
Everything feels important, so nothing gets prioritized
Great strategy session, zero follow-through
So I rebuilt my #1 GTM planning workshop inside Miro - with an AI agent “GTM Strategist” Sidekick trained on my book and checklist to power up the process.

I’ve run this workshop more times than I can count. The framework never changed.
What changed is that now you don’t need me in the room.
(free access)
Dear GTM Strategist,
In my ideal world, my content team would consist of 8 AI agents that would transform my call recordings into snappy LinkedIn posts and long-form Substack. 🤡
In the real world, I spend 20 hours/week working on content, we have an editorial and design team, and I am still scratching my head about how to speed up our content production with AI without compromising the quality and brand voice.
Claude Code was a big unlock on this journey since I could finally create context once, and then it knew our business, ICP, and branding essentials without dramatic flights in prompts and projects setups that produce various inputs.
Still, I keep hunting for more structured, end-to-end examples of how GTM operators are doing this - and ironically, I found one of the best in the LinkedIn comments.
Benjamin Gibert is the CMO of Base Operations, a B2B SaaS platform selling street-level threat intelligence to corporate security teams and government agencies. It is a series A startup with ~40 people. Ben does not have a dedicated content team. He is building an AI-native GTM strategy using agentic systems, but he can not get away with AI slop in a field that requires high trust.
Yet, his best marketing coworker is Claude Code.
Benjamin has built a content system that takes structured company knowledge, regularly enriches it with real customer conversations, and turns it into SEO articles, LinkedIn posts, ABM personalization, and even product strategy inputs.
Stuff that we like to call content engineering - the post you’re about to read is the most concrete walkthrough of how to actually do it that I’ve come across. Directory structure, agent specs, where the human review gates sit, which integrations matter and which don’t. He’s also open-sourced the whole thing on GitHub, so you can pressure-test it on your own setup.
Everything that we’ll present is done purely with the Claude Code and some power-up tools in the price range of SMEs. In other words, you can do it too!
Benjamin, how can we set up AI content workflows that produce content that is factually true and actually produces pieces that our ICP appreciates, instead of calling them AI slops?
Everyone in GTM is trying to figure out how to build content workflows that drive pipeline and revenue with AI. The problem is that if your AI-generated content is indistinguishable from your competitor’s AI-generated content, it won’t make any difference.
I run marketing for Base Operations, a B2B SaaS platform that provides street-level threat intelligence to corporate security teams. Most of my working hours are inside Claude Code. Over the past 14 months, I’ve learned (mostly through painful trial and error) how to build a content system that takes sales call transcripts and produces SEO/AEO articles, LinkedIn thought leadership posts, ABM personalization inputs, product strategy insights, and ultimately helps refine our targeting and GTM strategy.
Sales calls have always been a goldmine of customer insights. AI gives you a unique opportunity to turn that into the fuel for your GTM engine, but how you set up your system is the difference between sophisticated slop and differentiated content that converts your ideal buyer.
This post walks through how the system works: the knowledge foundation, the intelligence extraction, the pipeline stages, and the tool integrations that close feedback loops. I’ll also share the framework that puts it all in context, and point you to an open-source repo where you can build your own version.
The pipeline is the second thing I built. The first was the knowledge foundation underneath it, which is the context that matters most.
The Sophisticated Slop Problem (And What Solves It)
I’ve seen a lot of B2B teams embrace AI for content and fail. They build elaborate AI workflows that produce output that looks good only on the surface. I’m sure you’ve seen it. It reads well, hits the right keywords, and feels well-researched. And it says absolutely nothing a competitor couldn’t copy-paste, swap in their logo, and publish tomorrow.
I call this “sophisticated slop.” It passes every surface-level quality check, but it ranks nowhere and converts nothing, because search engines and buyers can both tell when content lacks genuine specificity. It erodes trust in humans and it doesn’t get ranked by algorithms, which are quickly adapting to the flood of AI content.
I made this mistake myself early on. My first attempt at a content pipeline had impressive multi-step workflows, carefully written prompt files, and zero strategic or tactical context beyond basic company information and target audience. After over a decade writing B2B content and managing content teams, I was so excited about building the pipeline architecture that I didn’t pause enough to evaluate how differentiated the output actually was.
Then I realized 90% of output quality comes from what you feed the system, not from the sophistication of the agents. This sounds obvious, but it’s easy to miss. Simple agents reading rich, specific context will outperform complex agents reading thin context every time.
A useful gut check: could a competitor copy-paste this output and change the logo? If yes, it’s slop regardless of how impressive the pipeline or how sophisticated the content sounds. That test has everything to do with whether the system contains genuine intelligence about your market, your customers, and your competitive position.
The fix is context engineering: building something substantial before you build the first agent. If you take one thing from this post, it’s that the quality of what you feed the system determines output quality more than any skill architecture. And the act of writing that context (documenting your ICP with real data, articulating positioning based on differentiated value, codifying voice rules with anti-patterns) forces the strategic clarity that makes everything downstream specific.
The Knowledge Foundation
The foundation of the system is a modular context architecture that lives in Github: a structured set of interconnected files that agents consume selectively.
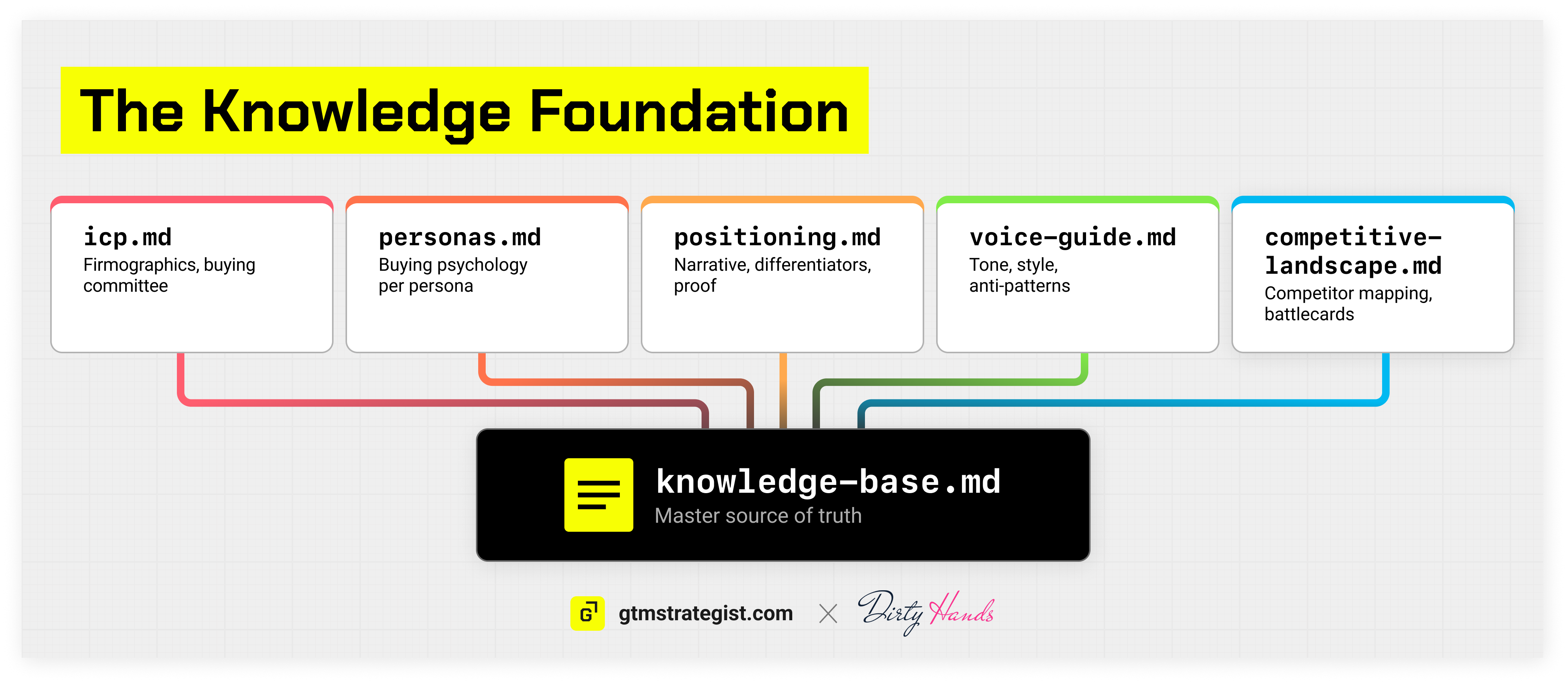
The master knowledgebase is the source of truth. One document containing positioning, ICP definition, persona profiles with buying psychology, voice and style rules, competitive landscape, proof points with metrics, and messaging framework. For Base Operations, this covers everything from our three core points of view to prohibited terminology to how we talk differently to a CSO versus a security analyst.
From the master, I derive scoped module files that agents actually consume:
icp.md-- firmographics, technographics, tiered customer profiles, buying committee roles, team structure, external signals that indicate a company is in-marketpersonas.md-- per-persona buying psychology, pain points in their language, decision criteria, common objections, content preferences, and where they spend time onlinepositioning.md-- strategic narrative, points of view and insights that ladder to them, differentiators with proof points, value propositions mapped to specific painsvoice-guide.md-- tone rules, voice guidance, style and editorial standards, anti-patterns (no “it’s not X, it’s Y”), a list of prohibited terms (no “seamless” or “revolutionary”)competitive-landscape.md-- competitor mapping, battlecard data, positioning gaps to exploit
The cascade principle makes this maintainable. When positioning changes, I edit the master knowledgebase, run a sync skill, and every derived module updates. Every agent that reads those modules produces different output on its next run. Maintain in one place, consume in many. Without this, you end up maintaining the same positioning language in 15 different prompt or skill files, and they drift within a week.
Why modular instead of one big file? Each skill specifies exactly which context files it reads. The research agent reads ICP, competitive landscape, and customer intelligence. The writer reads voice guide, positioning, and the approved outline. Tight context scoping produces better output, uses fewer tokens, and reduces the chance of an agent pulling irrelevant information into its reasoning.
The customer intelligence layer is where the real differentiation lives. We’ve extracted hundreds of structured insights from sales call transcripts across six dimensions: jobs to be done, customer problems, workflow reality, buying decisions, competitive intelligence, and product-market fit signals. These are structured JSON with exact customer quotes, speaker context, pain triggers, cost estimates, and urgency signals for every call.
This is the raw material that makes content sound like a practitioner wrote it instead of a marketing team. When a security director at a Fortune 500 retailer says “We have 80,000 employees. Realistically, we have budget to monitor threats for maybe 50 of them. The executives. Everyone else, we just hope nothing happens,” that quote, properly anonymized, does more work than any marketing copy I could write. It names the impossible math that every security leader knows but nobody talks about in vendor conversations.
The intelligence layer also includes a customer language lexicon: the specific terms buyers use versus the terms marketing teams use. In our market, customers say “single pane of glass” while marketers say “end to end platform.” Customers say “I need to know what’s happening on this block” while marketers say “hyperlocal situational awareness.” When your content uses the customer’s language, it feels like a peer wrote it. When it uses marketing language, it feels like a vendor wrote it.
The proof library completes the foundation: case studies with quantifiable metrics (”70% reduction in assessment time,” “5x increase in location coverage”) mapped to specific value propositions. Every claim the system makes in an article is backed by a specific number from a specific customer outcome. Claims without proof are invisible to both search engines and skeptical buyers.
All of these files are in markdown. This is the most effective format for AI agents to search and cross-reference while minimizing token costs. Plain text, version-controlled in git, readable by any agent without special parsing.
Here’s what the directory structure looks like:
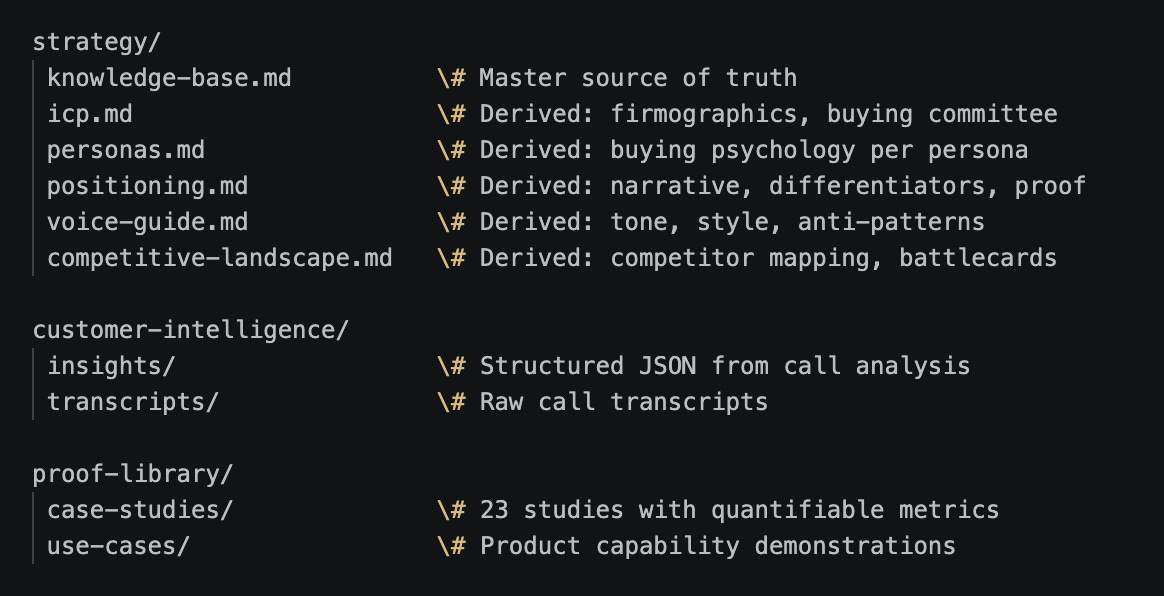
A side benefit I didn’t anticipate: once your GTM assets are structured like this in a repo, every file becomes searchable and cross-referenceable by Claude Code. You can ask research questions across your entire customer intelligence base (”Which pain points come up most often in enterprise healthcare calls?” or “What do prospects say about Competitor X’s pricing?”) and get answers grounded in your actual data. The structured repo becomes a research tool in its own right. And you aren’t locked into your call recording vendor’s credit system, pricing, or schema markup.
One Input, Multiple Outputs: The Customer Intelligence Multiplier
This is the strategic idea that changed how I think about content engineering. A single structured extraction from a sales call produces intelligence that feeds every GTM motion.
The call analyzer takes a raw transcript and produces structured JSON. The extraction runs through a Claude Code skill with a detailed system prompt specifying the exact output schema. You drop a raw transcript from any call recording tool (Gong, Fathom, Otter, or even manual notes) and the skill produces the structured JSON. The prompt and example output are both in the repo. The JSON output covers:
Jobs to be done: what the customer is trying to accomplish and why, with desired outcomes
Pains with context: specific problems, triggers, costs (time, risk, money), urgency signals
Workflow reality: current processes, manual steps, spreadsheet hacks, brittle integrations
Competitor mentions: brands trialed, workarounds used, sentiment toward each
Customer lexicon: exact phrases customers use versus marketing-speak, including “deviant” terms (the non-obvious ways buyers describe your category)
Keyword candidates: scored by buyer intent (35%), differentiator fit (20%), SERP weakness (15%), business priority (10%), mini-volume plausibility (10%), and authority fit (10%)
That structured output feeds:
SEO and AEO articles via the content pipeline (the detailed example below). Pain-point keywords, buyer language, and evidence from the call become the raw material for articles that rank because they contain genuine specificity.
LinkedIn thought leadership through a parallel pipeline. The same call produces anonymized customer quotes, tension hooks (”80,000 employees, budget for 50”), and persona-specific framing for founder content.
ABM personalization through persona-specific pain points, industry patterns, and objection mapping that flow into outbound sequences. When an outbound email references the exact workflow problem a prospect’s peer described on a sales call, the response rate is categorically different from a generic insight and ask.
Product and GTM strategy through JTBD pattern analysis, feature request clustering, and competitive intelligence aggregation across calls. When three different security directors independently describe the same gap in their workflow, that’s a signal your product team needs to hear. The structured extraction makes that pattern visible.
There’s also a compounding effect on your strategy itself. Run the call analyzer systematically across all of your sales conversations and patterns emerge that inform your ICP and persona definitions upstream. We discovered that mid-market security teams react to AI in security fundamentally differently from enterprise teams, which led us to split a single persona into two with different content strategies. That insight came from structured analysis of 150+ calls, not from any individual conversation.
A note on cadence: this kind of strategic update to ICP and positioning should happen every 3-6 months based on accumulated evidence, not in reaction to every call. Run the analysis, surface the patterns, then take findings through a structured review with your team. AI surfaces what’s changing; humans decide what to integrate.
One conversation with multiple structured outputs. Each feeding a different system that consumes only the dimensions it needs. The call analyzer produces comprehensive structured intelligence, and each consuming system takes the slices it needs. Before building this, I was treating each GTM motion as a separate content creation problem. Reframing it as an intelligence distribution problem improved the compounding impact of the whole system.
The Content Pipeline: Stage by Stage
Here’s the SEO/AEO pipeline as one detailed example. This is the system that produces differentiated articles that rank, grounded in sales call intelligence no other company has.
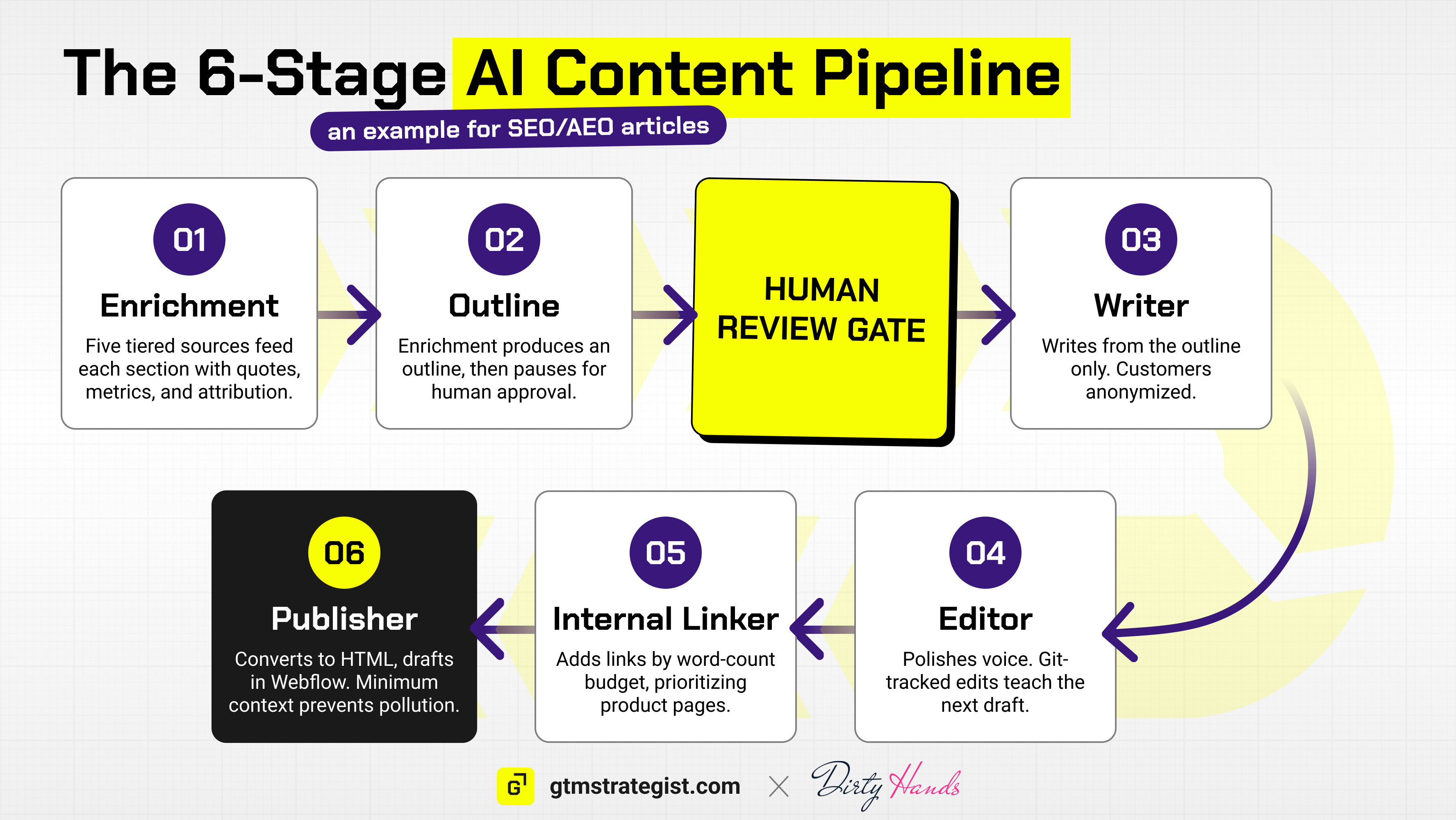
The system can produce articles as fast as you can review them. The bottleneck is the human in the loop at the outline stage and final review, which can take at least 15-20 minutes per article. The results have been meaningful: organic traffic doubled over 3-4 months, AEO citations increased 500-600%, and we’ve ranked #1 on Google for core terms within weeks of publishing, resulting in inbound increasingly driving more demo calls and pipeline.
Research and Intelligence Layer
The pipeline starts before any writing happens, with two agents doing the strategic work.
The Call Analyzer (built on Grow & Convert’s Pain-Point SEO methodology) processes a transcript and produces the structured JSON I described above. It prioritizes buyer intent over search volume, captures exact customer phrasing rather than generic summaries, and maps every finding to specific keyword types: category searches, comparison queries, JTBD queries, and deviant terms.
The Research Agent takes the call analyzer output across hundreds of calls and produces two things: a prioritized topic backlog scored by pain-point SEO criteria, and detailed content briefs for selected topics.
The brief is the part that tends to surprise people. It’s a structured JSON document specifying everything a downstream agent needs:
{
“meta”: {
“topic_id”: “GC-202501-security-platform-guide”,
“priority_score”: 4.3,
“stage”: “BOFU”,
“format”: “guide”
},
“keyword”: {
“primary”: “security intelligence platform”,
“variants”: [”threat intelligence software”, “risk assessment platform”],
“searcher_intent”: “Category”
},
“audience”: {
“persona”: “Global Security Director”,
“pain_summary”: “Spending 20+ hours manually gathering threat data”
},
“value_props_to_weave”: [
{
“pain”: “Manual research bottleneck”,
“prop”: “5x faster threat assessments”,
“proof”: “Case Study: Fortune 500 Security Team”
}
],
“originality_nuggets”: [
{
“type”: “quote”,
“source”: “Sales transcript - Fortune 500 retail”,
“owner”: “Content team”
}
]
}The brief specifies the keyword, the searcher’s intent, the target persona, the specific angle, a section-by-section outline, which value propositions to weave in (mapped as pain to proposition to proof), originality requirements, internal link targets, and SEO metadata.
The research agent consumes icp.md, personas.md, competitive-landscape.md, and the customer intelligence directory. It never sees the voice guide or the full knowledgebase. It gets exactly the context it needs for strategic research decisions and nothing else.
Enrichment and Outline
Stage 1 (Enrichment): The brief gets enriched by mining five tiers of context sources in priority order:
Structured JSON insights (the fast path: already tagged by persona and use case)
Case studies (metrics, customer outcomes, before/after comparisons)
Use cases (workflow demonstrations, product capabilities)
CSV insights database (pattern-level evidence across multiple calls)
Full transcripts (deep path, last resort for specific unfilled gaps)
Evidence gets mapped to each section of the brief with specific quotes, metrics, and source attribution. The actual quote, the actual number, the actual speaker role and industry context.
Stage 2 (Outline): The enrichment output merges with the brief structure into a writer-ready outline. Each section includes word count targets, specific proof points assigned with full text, AEO formatting directives (definition boxes, comparison tables, numbered processes), and entities to mention.
Then the pipeline stops.
This is deliberate. The human review gate sits between research and execution. You review the outline, adjust the emphasis, approve or reject evidence choices, and rename the file to _outline-approved.md before the pipeline continues. Human judgment at the strategic inflection point, not at the copy-editing stage where it’s too late to change direction.
Write, Edit, Link, Publish
Stage 3 (Writer): Writes from the approved outline, consuming only voice-guide.md, positioning.md, and the outline itself. The outline carries all the evidence forward, so the writer agent never needs to search the knowledgebase. The outline is the information boundary. Everything the writer needs is already in it. No searching, no improvising, no pulling in context that wasn’t approved.
The writer follows specific patterns. Feature to Benefit to Proof: mention a capability, explain why it matters to the reader, prove it with a specific metric or customer outcome. Value propositions as undercurrent: threaded throughout the piece at natural moments, never isolated into a “Why Our Product” section. Customer anonymization applies during writing: “Bob Rendle, Director of Crisis Management at Compliunce” becomes “the Director of Crisis Management at a Fortune 500 insurance and risk management company.” Keep the title, the industry, the company scale. Remove the name and the brand (unless you can get approval).
Stage 4 (Editor): Style enforcement, terminology standards, prohibited language removal. Reads only voice-guide.md. Catches any remaining drift from brand voice, eliminates weak qualifiers, scrubs obvious AI-writing tells, and ensures consistent terminology. If Stage 3 did its job, Stage 4 makes minor adjustments.
Here’s where another compounding loop lives. After every human editorial pass, everything is tracked in git. A Claude skill tracks the diff between the AI draft and my edited version, and the system analyzes what I changed: which phrasings I rewrote, which claims I softened, which sections I restructured. Those patterns get fed back into the agent’s prompt and workflow rules. The editor that produces draft 15 has internalized lessons from my edits on drafts 1 through 14. This is slow, unglamorous improvement, and it’s the kind of thing that adds up over months.
Stage 5 (Internal Linker): Calculates a link budget based on word count (an 800-1,500 word article gets 5-8 links; a 2,500+ word piece gets 10-15), then distributes priority URLs across the article. Core product pages get priority, then case studies, then other articles. Reads only the sitemap. Hard rules: max one link per paragraph, no duplicate destinations, anchor text must already exist naturally in the prose.
Stage 6 (Publisher): Markdown to HTML conversion, FAQ JSON-LD schema generation for rich snippets, category detection based on content analysis, related article suggestions via keyword matching against the sitemap, and Webflow CMS draft creation. Reads only the SEO assets YAML file generated back in Stage 2.
Each stage loads the minimum context it needs. The pipeline architecture enforces this: no stage has access to more than it requires. This prevents context pollution, where an agent with too much information starts making connections the outline didn’t authorize. I learned this the hard way when an early version of the writer agent had access to the full knowledgebase and kept inserting product mentions that the outline hadn’t approved that didn’t make sense. Everyone who has built with AI knows this pain. Constraining context solved it overnight.
Where Tool Integrations Close the Loop
The pipeline works with Claude Code and local files. No external integrations are required. But the system gets meaningfully more powerful when you wire in data sources through MCP (Model Context Protocol) or CLI (Command Line Interface).
Firecrawl gives the research agent automated SERP analysis. Instead of guessing what’s ranking for a target keyword, it can crawl the top results, identify content gaps, and build briefs informed by what’s actually out there. The enrichment stage can pull competitor content analysis into the evidence map.
HubSpot connects deal data to content prioritization. Which pain points correlate with deals that closed won? Which personas engage with existing content? This turns topic selection from educated guessing into one informed by the fastest closing deals in our CRM.
Clay enriches companies mentioned in transcripts to surface industry patterns across the customer base. When you see that the same workflow problem appears across retail, financial services, and healthcare, you know it’s worth a dedicated article rather than a throwaway mention.
Lemlist (or any outbound sequencer with an API) connects the intelligence layer directly to outbound execution. The same persona pain points, customer language, and objection mapping that feed your content pipeline can also draft multi-channel outbound sequences. Combine structured call insights with an outbound email skill that knows your voice rules and you can go from “interesting pattern in our sales calls” to “personalized 3-step sequence loaded in the sequencer” in a single session. The intelligence does double duty.
Webflow is already in the pipeline. Stage 6 creates a CMS draft directly, with FAQ schema, category detection, and related article suggestions. No copy-paste or manual formatting. The human in the loop is for editorial standards, not copy-pasting markup into your CMS.
Analytics feedback is the loop that makes the system compound. Which articles drive pipeline? Which briefs produce content that ranks? Which topics drive demo requests versus bounces? That performance data flows back into the research knowledgebase, updating priority scores and informing future topic selection. The research agent building brief number 120 has access to performance data from briefs 1 through 119. It knows which angles worked, which personas engaged, which content formats converted. This is where the system starts to learn, and it’s the difference between a content production line and content infrastructure.
The core pipeline works today with Claude Code and local files. Every MCP integration is an optional enhancement. You don’t need all of them to start. You add them as your system matures and the feedback loops become worth closing.
The Bigger Picture: From One Motion to a Compounding System
The content pipeline is one motion in a larger system. I want to zoom out briefly because the architecture pattern transfers to other GTM motions.
I’ve come to think about AI-native GTM as four layers:

Layer 1: Human Strategy and Creative Direction. The modular context files I described. Positioning, ICP, personas, voice guide, competitive landscape. Written by humans, consumed by AI. No agent replaces the judgment that goes into sharp positioning.
Layer 2: AI as Thought Partner. Using AI to pressure-test strategy, explore alternative angles, deepen thinking, test against persona councils. Augmenting human reasoning, not replacing it.
Layer 3: AI-Powered Systems. The content pipeline lives here. So does signal-based outbound, demand gen campaigns, customer intelligence extraction, competitive monitoring, and lifecycle campaigns. Each motion follows the same pattern: signals trigger workflows, workflows produce outputs, quality gates enforce standards.
Layer 4: The Practical Architecture. Claude Code, MCP integrations, skill files, the directory structure that makes it all work. The architecture compounds: every reference file makes every skill more effective. The marginal cost of the 20th skill is far lower than the first.
The learning loop connects execution back to strategy. Content performance data updates the research knowledge base. Outbound response rates refine persona models. Customer intelligence from new calls enriches the foundation. Feedback flows upstream, and the system gets better with each cycle.
The critical insight at every transition between layers: the jump is never about discovering a better tool. It’s about restructuring how work is represented. From conversations to files. From files to skills. From skills to pipelines with learning loops.
One thing that makes the system genuinely extensible is that clear structure in the repo means adding new inputs is straightforward. When I added dedicated competitive intelligence pages for each of our main competitors, every skill that consumed competitive-landscape.md immediately had richer context. That opened the door to competitor-specific content pipelines (comparison articles, alternative pages) that would have required a separate research effort before. The structured foundation means new capabilities often emerge from adding a new file to the right directory.
A helpful way to think about where you are today:
Level 0 (Ad-hoc): Copy-paste into AI chat. Re-explain your company every session.
Level 1 (Documented): ICP, positioning, voice rules exist as files AI can read in Claude projects or Custom GPTs.
Level 2 (Assisted): AI drafts following your strategy. Skills extract insights, write articles.
Level 3 (Systematic): Signal-to-workflow-to-output patterns for each GTM motion.
Level 4 (Compounding): Performance data updates strategy. The system learns from every execution cycle.
The content pipeline I walked through operates at Level 3, moving toward Level 4 as the analytics feedback loop matures. The jump from Level 0 to Level 1 is the hardest, and also the most valuable even if you stop there. Writing a detailed ICP document for an AI to consume forces you to actually have a detailed ICP. Articulating positioning with proof points for a skill file to reference forces you to actually have sharp positioning. The foundation-building work makes your GTM better whether or not you ever build the pipeline on top of it.
Try It Yourself
I’ve open-sourced a generalized version of this system as a GitHub repository. It includes:
Example files from a fictional B2B SaaS company showing what good looks like at each stage (fully written examples you can study, not placeholders)
Strategy templates that Claude Code walks you through interactively to build your knowledge foundation
Execution skills: call analyzer, research agent, the full 6-stage SEO pipeline, LinkedIn insight extraction
A sync skill that cascades master knowledge base edits to all derived module files
An onboarding agent (via CLAUDE.md) that detects your setup state and guides you through building your own version
Clone it. Open Claude Code. The system walks you through creating your knowledge foundation first, then running the pipeline.
Get the repo by Subscribing to Dirty Hands.
The repo is designed to grow. The content pipeline is the first fully built motion I’m offering for free.
I get asked for advice on AI all the time, so I’m launching the Dirty Hands GTM newsletter to share what I’m building for GTM (and selfishly to force myself to clarify my thinking on this). It’s one of the wildest and most exciting times to be in B2B marketing if you love getting your hands dirty and building. It’s a cliché because it’s true.
Every week, I’ll break down one system like this in Dirty Hands, a newsletter for GTM operators who build with AI. Real systems with catalogued results and failures.
Future issues of the newsletter will add new motions to the repo: signal-based outbound, content repurposing, customer intelligence extraction, competitive monitoring. Each new motion adds skills, so you have a reason to keep coming back as the system expands.
If this walkthrough was useful, the newsletter goes deeper.
Subscribe to Dirty Hands on Substack

✅ Need ready-to-use GTM assets and AI prompts? Get the 100-Step GTM Checklist with proven website templates, sales decks, landing pages, outbound sequences, LinkedIn post frameworks, email sequences, and 20+ workshops you can immediately run with your team.
📘 New to GTM? Learn fundamentals. Get my best-selling GTM Strategist book that helped 9,500+ companies to go to market with confidence - frameworks and online course included.
📈 My latest course: AI-Powered LinkedIn Growth System teaches the exact system I use to generate 7M+ impressions a year and 70% of my B2B pipeline.
🏅 Are you in charge of GTM and responsible for leading others? Grab the GTM Masterclass (6 hours of training, end-to-end GTM explained on examples, guided workshops) to get your team up and running in no time.
🤝 Want to work together? ⏩ Check out the options and let me know how we can join forces.
 | A guest post by
|
Loved working on this with you @Maja Voje ! Hope the community finds the detailed walkthrough and github repo to build it themselves useful.
This is incredibly helpful thank you. Subscribed to Dirty Hands :) Btw, I know you have the GTM masterclass… curious if you’ll ever have a course combining Claude code x GTM that covers everything for example that was mentioned in this post?